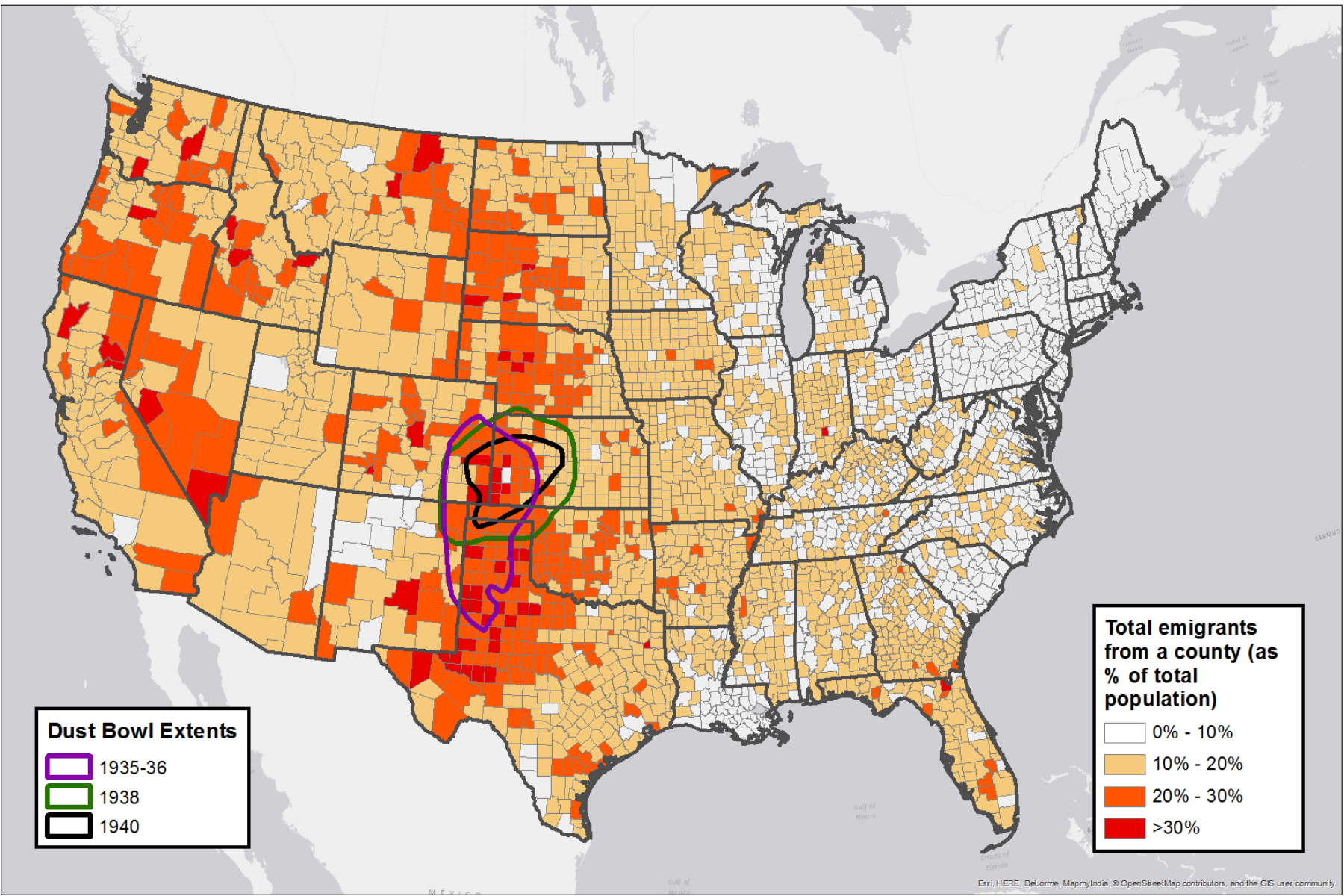
The explanation for the wide-spread emigration became clear after examining climate maps. These maps showed that drought and high temperatures plagued all of the Plains states from Texas to Montana. Much earlier scholarship focused on the Dust Bowl region, whose experiences were widely publicized by journalists, photographers, and later authors. A larger, quantitative analysis - with the aid of digital mapping - makes evident the much wider extent of this environmental disaster.
Mikecz
Migration in the Depression-Era United States
Explaining why people moved in the 1930s United States
For two years, within the Institute of Behavioral Science at the University of Colorado, I worked with Dr. Myron Gutmann and Angela Cunningham on a digital history study of migration. This project was based on special access the Institute had to a restricted dataset: individual data for 131 million Americans recorded in the 1940 United States population census. In this census, every household was asked where they had lived five years prior in 1935. Of seventy-eight million adults twenty years or older in this dataset, approximately ten percent had moved to a new county since 1935.
In this project, we contextualized this individual dataset with a variety of county-level data to help explain why people moved. This county-level data included:
- County-level data from the Agricultural Censuses of 1930, 1935, and 1940.
- County-level demographic and economic data from the Population Censuses of 1930, 1935, and 1940
- Temperature and precipitation data aggregated to annual averages for every county, 1920-1940
The first question asked was: what factors caused people to move?
Why did people move?
My research partners conducted statistical regression analysis to identify which of our thousands of county-level variables was most correlated with the decision to move out of a county. Meanwhile, I constructed a series of county-level chloropleth maps to explore the spatial variation of these various factors. The map below, for example, plots the rate of emigration for each county in the United States, between 1935 and 1940. Laid over this map are outlines of the regions devastated by the wind and dust storms of the "Dust Bowl." The most interesting thing to note is that the Dust Bowl region - the focus of most research on environmental disaster and migration during the 1930s - forms just one small part of a much larger region experiencing high-outmigration during the period. As can be seen here, counties from the Texas-Mexico border to northeastern Montana saw high proportions of their residents move out, with many counties losing 20% or more of their residents in 1935.
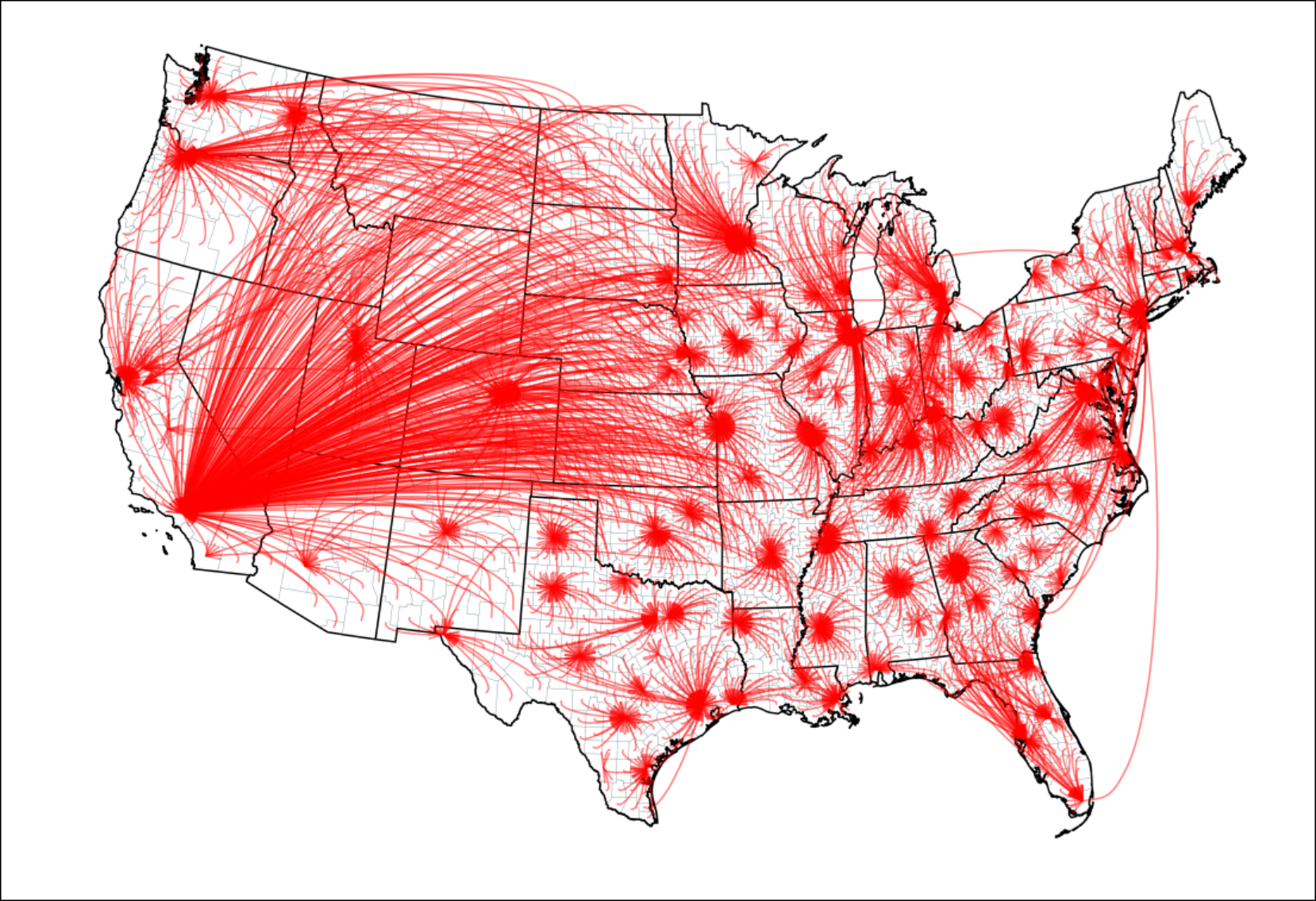
Why did people move where they did?
Next, we turned our attention to the question of why people moved where they did. In particular, we examined links between origin and destination locations by constructing a database of origin-destination pairs. Our previous analysis had relied on data for the approximately 3000 counties* in our project, computing the number of emigrants who left each county after 1935 and the number of immigrants who arrived before 1940. The origin-destination pairs dataset, however, compiled data for the number and demographics of all people who moved from County A to County Z, for example. Thus, each of the nearly 3000 counties* in our dataset had nearly 3000 potential pairs, meaning this dataset could potentially include nine million (3000 x 3000) observations. However, most lightly populated counties only saw migrants leave for a small handful of other counties, usually to neighboring rural counties or the nearest metropolitan area. In the end, this origin-destination pairs dataset ended up containing approximately 600,000 pairs.
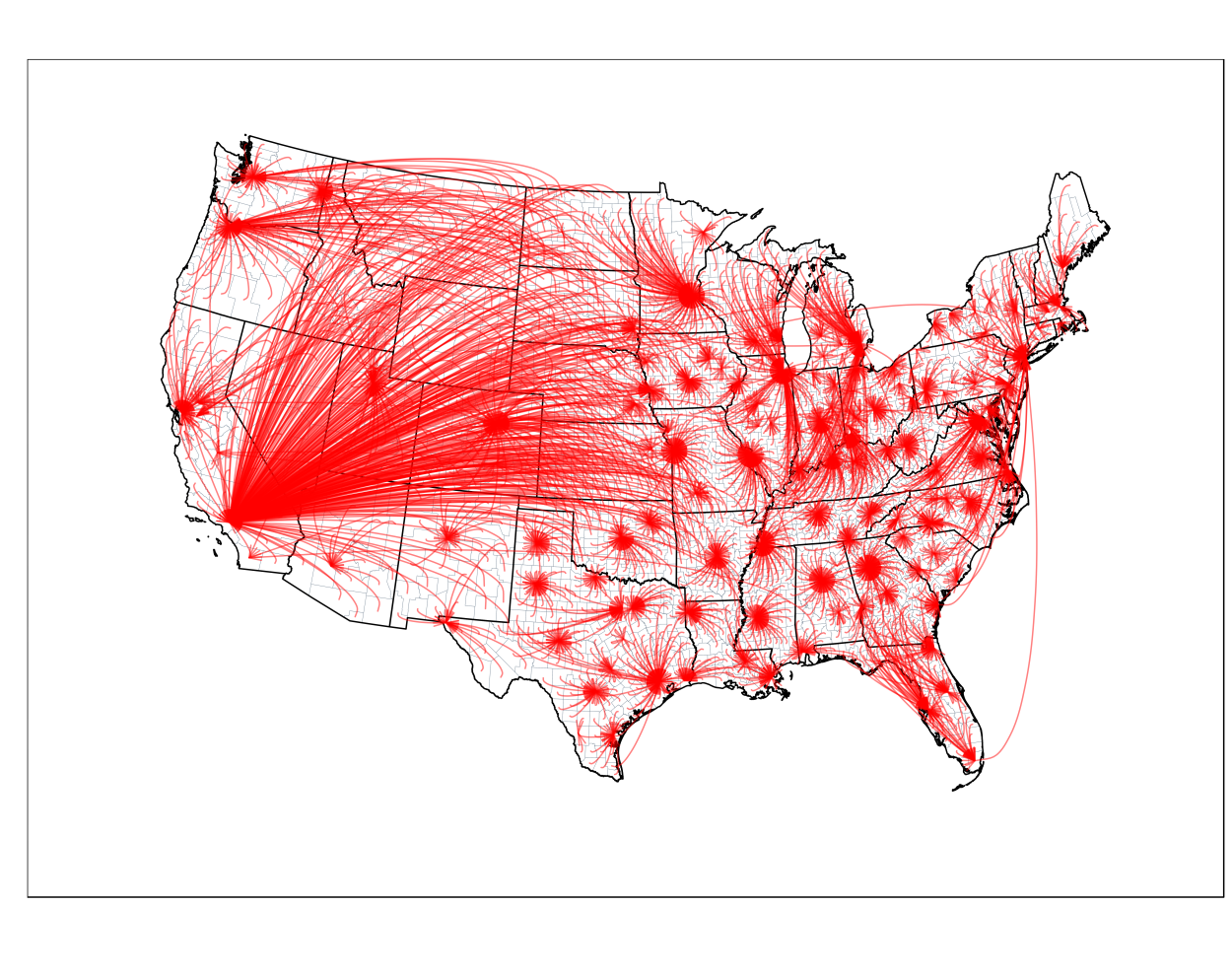
The map above plots the most frequent metropolitan destinations for emigrants leaving each non-metropolitan county. The majority of counties "sent" most of their emigrants to nearby metropolitan areas with two exceptions. In the first, some major metropolitan areas pulled migrants from slightly further away. These are places like Detroit, Chicago, and New York. The second exception is Los Angeles and southern California more generally. It was the top metropolitan destination for many rural counties in the Great Plains.
Aggregating Data

content