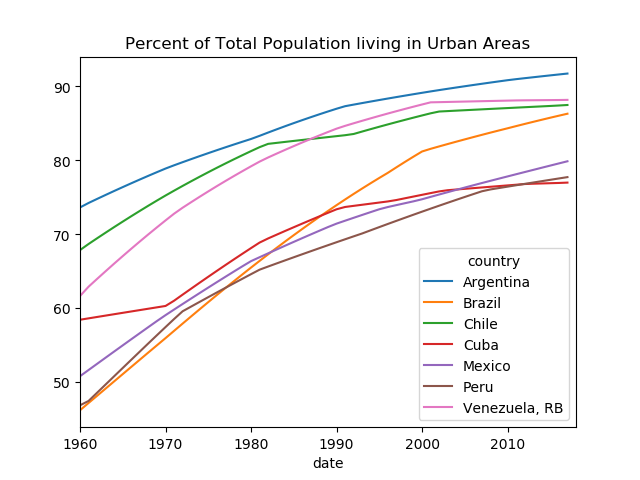
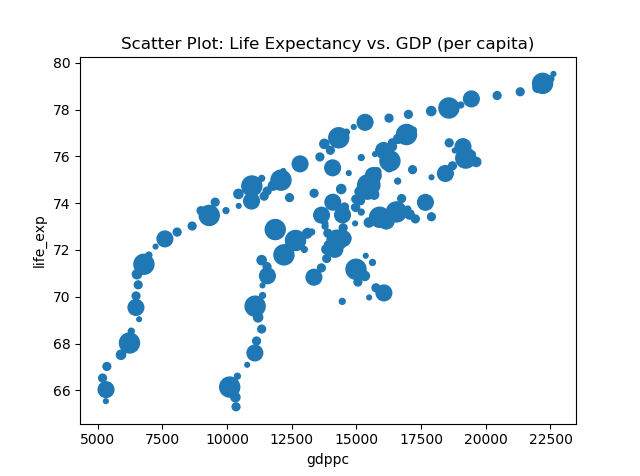
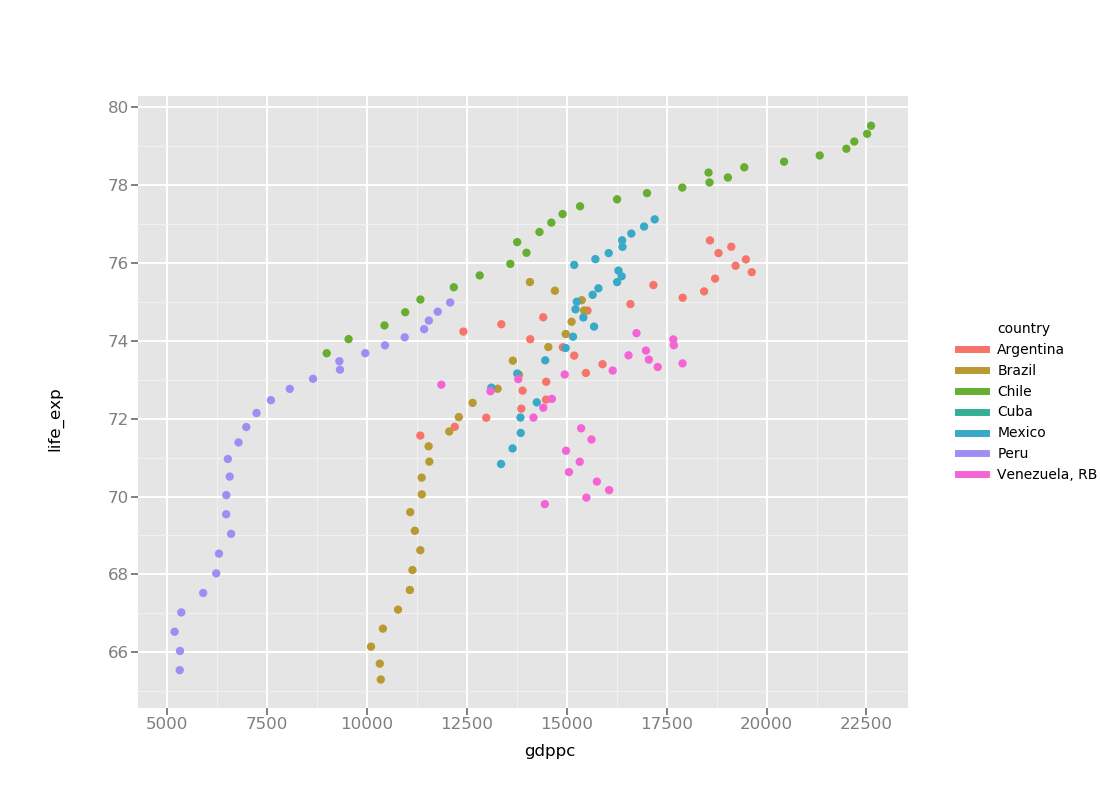
Here is the code:
import wbdata
import pandas as pd, numpy as np
import os
import plotly.plotly as py
import plotly.graph_objs as go
lqregs=pd.read_csv('lifeQ_regs.csv') #imports my dataset of Quality of Life data for continents / regions (life expectancy, gdp, literacy, net migration, malnourishment, etc.)
lqLA=pd.read_csv('lifeQ_LatAm.csv') # same as above but with Latin American countries
lqLA['text']=lqLA['country']+' ' +lqLA['date'].map(str) # creates a new variable that combining the country and date into one variable (i.e. "Argentina 1991") for ease of display in my chart
lqLA['tpop_millions']=lqLA['totalpop']/1000000 #creates a new variable recording total population in millions
lqLA2=lqLA.dropna(subset=['tpop_millions']) #removes all instances (rows) missing total population data
#not sure what this does, but I plugged in the name of my dataframe ("lqLA2") and the variable I want to use to set the size of each point ("tpop_millions")
sizeref = 2.*max(lqLA2['tpop_millions'])/(100**2)
# in plotly we need to separate code for each country if we want to display them with different colors.
# for trace0 I modified all the code to call the dataframe and variables I am using. Then I set the country to 'Argentina'
# I also set the color for Argentina using [rgb codes](https://www.rapidtables.com/web/color/RGB_Color.html).
trace0 = go.Scatter(
x=lqLA2['gdppc'][lqLA2['country'] == 'Argentina'],
y=lqLA2['life_exp'][lqLA2['country'] == 'Argentina'],
mode='markers',
name='Argentina',
text=lqLA2['text'][lqLA2['country'] == 'Argentina'],
marker=dict(
color='rgb(93, 164, 214)',
symbol='circle',
sizemode='area',
sizeref=sizeref,
size=lqLA2['tpop_millions'][lqLA2['country'] == 'Argentina']/4,
line=dict(
width=2
),
)
)
#then for traces 1-6 I just copied my modified code from trace0, only needing to modify the country name (5x each) and the color for each trace.
trace1 = go.Scatter(
x=lqLA2['gdppc'][lqLA2['country'] == 'Brazil'],
y=lqLA2['life_exp'][lqLA2['country'] == 'Brazil'],
mode='markers',
name='Brazil',
text=lqLA2['text'][lqLA2['country'] == 'Brazil'],
marker=dict(
color='rgb(255, 144, 14)',
symbol='circle',
sizemode='area',
sizeref=sizeref,
size=lqLA2['tpop_millions'][lqLA2['country'] == 'Brazil']/4,
line=dict(
width=2
),
)
)
trace2 = go.Scatter(
x=lqLA2['gdppc'][lqLA2['country'] == 'Chile'],
y=lqLA2['life_exp'][lqLA2['country'] == 'Chile'],
mode='markers',
name='Chile',
text=lqLA2['text'][lqLA2['country'] == 'Chile'],
marker=dict(
color='rgb(44, 160, 101)',
symbol='circle',
sizemode='area',
sizeref=sizeref,
size=lqLA2['tpop_millions'][lqLA2['country'] == 'Chile']/4,
line=dict(
width=2
),
)
)
trace3 = go.Scatter(
x=lqLA2['gdppc'][lqLA2['country'] == 'Cuba'],
y=lqLA2['life_exp'][lqLA2['country'] == 'Cuba'],
mode='markers',
name='Cuba',
text=lqLA2['text'][lqLA2['country'] == 'Cuba'],
marker=dict(
color='rgb(70, 40, 171)',
symbol='circle',
sizemode='area',
sizeref=sizeref,
size=lqLA2['tpop_millions'][lqLA2['country'] == 'Cuba']/4,
line=dict(
width=2
),
)
)
trace4 = go.Scatter(
x=lqLA2['gdppc'][lqLA2['country'] == 'Mexico'],
y=lqLA2['life_exp'][lqLA2['country'] == 'Mexico'],
mode='markers',
name='Mexico',
text=lqLA2['text'][lqLA2['country'] == 'Mexico'],
marker=dict(
color='rgb(120, 240, 20)',
symbol='circle',
sizemode='area',
sizeref=sizeref,
size=lqLA2['tpop_millions'][lqLA2['country'] == 'Mexico']/4,
line=dict(
width=2
),
)
)
trace5 = go.Scatter(
x=lqLA2['gdppc'][lqLA2['country'] == 'Peru'],
y=lqLA2['life_exp'][lqLA2['country'] == 'Peru'],
mode='markers',
name='Peru',
text=lqLA2['text'][lqLA2['country'] == 'Peru'],
marker=dict(
color='rgb(180, 100, 245)',
symbol='circle',
sizemode='area',
sizeref=sizeref,
size=lqLA2['tpop_millions'][lqLA2['country'] == 'Peru']/4,
line=dict(
width=2
),
)
)
trace6 = go.Scatter(
x=lqLA2['gdppc'][lqLA2['country'] == 'Venezuela, RB'],
y=lqLA2['life_exp'][lqLA2['country'] == 'Venezuela, RB'],
mode='markers',
name='Venezuela, RB',
text=lqLA2['text'][lqLA2['country'] == 'Venezuela, RB'],
marker=dict(
color='rgb(240, 40, 160)',
symbol='circle',
sizemode='area',
sizeref=sizeref,
size=lqLA2['tpop_millions'][lqLA2['country'] == 'Venezuela, RB']/4,
line=dict(
width=2
),
)
)
#combines all the traces into one dataset
data = [trace0, trace1, trace2, trace3, trace4, trace5, trace6]
# sets the layout for the grid (axes, labels, color background, etc.)
layout = go.Layout(
title='Life Expectancy v. Per Capita GDP',
xaxis=dict(
title='GDP per capita',
gridcolor='rgb(255, 255, 255)',
zerolinewidth=1,
ticklen=5,
gridwidth=2,
),
yaxis=dict(
title='Life Expectancy (years)',
gridcolor='rgb(255, 255, 255)',
zerolinewidth=1,
ticklen=5,
gridwidth=2,
),
paper_bgcolor='rgb(243, 243, 243)',
plot_bgcolor='rgb(243, 243, 243)',
)
#puts it all together to create the plot.
fig = go.Figure(data=data, layout=layout)
url=py.plot(fig, filename='life-expectancy-per-GDP')